
Con más de 100 millones de usuarios registrados, 80 millones de productos ofrecidos a través de más de 80 categorías, y aproximadamente 8 millones de envíos hechos por mes, Flipkart—el mercado online más grande de India, comenzaba a perder clientes y experimentar un alto nivel de desinstalaciones de su app. Era claro que el equipo necesitaba pensar en una nueva estrategia para retener a esos clientes, así que rediseñamos la experiencia de usuario de la app de Flipkart.
Era crítico reveer la estrategia de UX y encontrar una solución que se centraría en diseñar una experiencia de usuario que forme hábitos, tener un impato substancial en los usuarios, y generalmente:
- Lograr una conexión más eficiente con los clientes
- Elevar la marca
- Encender el crecimiento
Los compradores online son notoriamente muy conscientes de los precios, y su lealtad es muy breve. La mayor parte del tiempo no les importa de qué sitio compren siempre y cuando obtengan la mejor oferta posible.

Es esencial hacer las siguientes preguntas de forma constante:
- ¿Cómo logras que los consumidores elijan tu eCommerce primero?
- ¿Cómo convences a los compradores que vean tus ofertas antes de compararlas contra tus competidores–que vean precios económicos y luego realizar una compra?
Estos son sólo algunos de los problemas apestando al equipo de product design de UX. Lo que viene a continuación es cómo lidiamos con ello.
Ganar Percepción Haciendo Preguntas Inteligentes
Se volvió obvio que ganar algún tipo de percepción en las opiniones de los consumidores, tendencias y hábitos de compra era crítico para entender el panorama de las compras online, el cual estaba constantemente cambiando, y la capacidad de optimizar la experiencia y satisfacción del cliente.

El equipo de Flipkart continuó preguntándose estas preguntas:
- ¿Cómo construyes una base leal de clientes e incrementar su participación?
- ¿Qué comportamientos deberían ser estudiados para obtener una solución ganadora?
- ¿Cómo construyes una experiencia de compra superior que contiene el instinto de buscar gangas y proveer algo de un valor duradero que haga que los clientes sigan volviendo una y otra vez?
- Y–por último, pero no menos importante–¿Cómo resuelves el problema de las desinstalaciones de la app?
Colaborando con otro Diseñador UX en muchas sesiones de brainstorming, se nos ocurrió un simple propuesta para repensar el UX y hacerlo algo subsequente en el rediseño de la app de Flipkart.
El núcleo de la solución era diseñar una experiencia que forme hábitos que contraste a la experiencia de compra usual de una app de eCommerce.
Pero primero, era necesario reconocer un par de desafíos básicos.
Desafío No. 1: Desinstalaciones de App
Los usuarios mobile tienen una relación frágil con las apps: Aman a algunas pocas que suelen conservar por siempre pero desinstalan a la gran mayoría de ellas que descargan. Voy a compartir un dato sorprendente: el 77% de los usuarios nunca usan una app de nuevo después de 72 horas de haberla instalado. Este porcentaje es un desafío para que los diseñadores hagan que las personas se enamoren con sus apps durante esa crucial primer semana.
Las apps más exitosas son aquellas que tienen un buen diseño conductual–esas apps ‘pegajosas’ que la gente usa de forma regular y no pueden imaginar su vida sin ellas.
Sitios de eCommerce dependenden en eventos de ventas de forma periódica. Estas ventas van desde la categoría de fechas festivas y otras especiales que no son necesariamente por fechas festivas. El “Amazon Prime Day”, por ejemplo, no coincide con ninguna fecha particular o venta anual—como el Black Friday—y sin embargo, Amazon consiguió hacer del Prime Day 2016 el día de compras más exitoso, opacando las ventas del Prime Day 2015 en más del 60% por ciento en todo el mundo.
En 2015, Flipkart vendió productos valuados en $300 millones de dólares durante el “Big Billion Day”, su equivalente de varios días al Amazong Prime Day. Durante la primer hora de venta, Flipkart tenía casi 140 órdenes por segundo. Las descargas de la app mobile de Flipkart suben significativamente cerca del Big Billion Day porque muchas de las ofertas estaban sólo disponibles para compradores a través de la app mobile.
Junto a otras grandes órdenes en el Big Billion Day, vemos una suba en el número de desinstalaciones de apps de forma inmediata a estos eventos. Entre los consumidores que descargaron la app mobile de Flipkart antes o durante el Big Billion Day, en promedio sólo un 30% han dejado al app en sus dispositivos año tras año desde el 2014. Los usuarios suelen dejar de usar la app una vez que las ventas terminan, por lo general debido a problemas de espacio que los Indios tienen en sus dispositivos mobile. (Muchos servicios de telefonía limitan a sus clientes a un total de veinte apps por dispositivo en India). Los consumidores eligen entonces sólo dejar en sus teléfonos las apps que usan de forma diaria, como Facebook, WhatsApp, o YouTube.
Decidimos indagar en profundidad en varias categorías de apps e identificar cuáles son ganadoras y cuáles perdedoras respecto a la lealtad de sus consumidores:
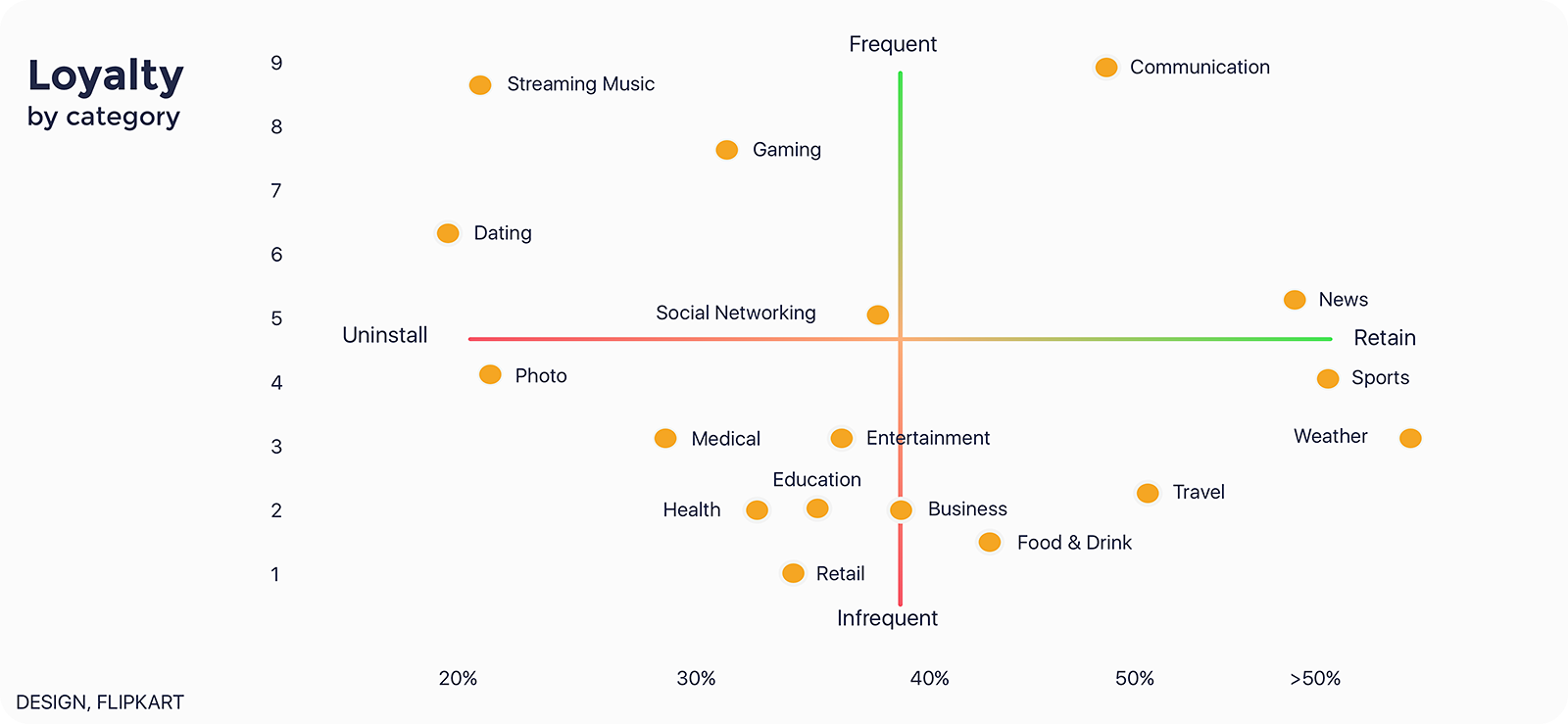
Noticias, Deportes, y el Clima están entre las categorías líderes en la escala de “retención” de usuarios. ¿Por qué? Todas estas apps forman hábitos, o sea, las personas siguen volviendo a ellas una y otra vez. Entonces, para mover su app a la zona de “retención”, Flipkart necesitaba crear una app que formase hábitos.
Pero, ¿qué es una app que forma hábitos? Para saberlo, primero necesitamos identificar los desafíos que enfrenta la lealtad en el eCommerce.
Desafío No. 2: Lealtad Cero
Los hábitos son acciones hechas con poco o nada de pensamiento consciente. Investigaciones sugieren que un 40% de lo que hacemos todos los días es por hábito. Nos enganchamos en hacer cosas de una cierta forma, y nos apoyamos en la consistencia y el confort que nuestros hábitos proveen. Por ejemplo, la industria del video juego ha utilizado concepto de gancho para hacer que sus usuarios vuelvan a jugar sus juegos por años.
La principal forma de “gancho” nos dice que un disparador causa en nosotros realizar una acción por la cual experimentaremos una recompensa. Esa recompensa hace que invirtamos en la acción que nos recompensa, guiándonos a más disparadores y así, perpetuar el ciclo.
No es un secreto que así es como los animales son entrenados.
El gancho comienza con un disparador en el ambiente del usuario. Estamos familiarizados con disparadores externos—por ejemplo, notificaciones sobre productos que nos interesa. Sin embargo, disparadores internos son más críticos en ayudarnos a formar un hábito duradero. Usamos muchas actividades habituales a lo largo del día para escapar de nuestro aburrimiento o, a veces, para salir de un estado emocional negativo y entrar a nuestra zona de confort. Por ejemplo, buscamos en Facebook e Instagram en un intento de mejorar nuestro humor al mirar GIFs animados de cachorritos o videos graciosos de gatos.
FOMO
Cada día cuando nos levantamos, muchos de nosotros sentimos el ‘miedo a perdernos algo’ (o FOMO, fear of missing out). Si revisas tu email, noticias, Facebook, Twitter, etc. ni bien te despiertas por la mañana, entonces ya sabes lo que está sucediendo en el mundo y por eso te sientes más conectado. El equipo de Flipkart vio una oportunidad para utilizar este disparador interno para iniciar su gancho.
La palabra FOMO (fear of missing out) fue de hecho añadida al Diccionario de Inglés de Oxford en el 2013. Aunque la terminología fue sólo recientemente añadida a nuestro léxico, el experimentar FOMO no es nada nuevo.

Para crear un gancho efectivo, necesitarás un patrón de UX viable. Y debes admitir que las notificaciones tradicionales pueden no funcionar bien por sus problemas inherentes; por ej. La ceguera de la notificación.
Flipkart tiene más de 80 millones de productos en más de 80 categorías, así que era importante para ellos categorizar y etiquetar el mar de productos disponibles y mapearlos con los intereses de los usuarios. Lo cual nos lleva al siguiente desafío…
Relevancia y Personalización
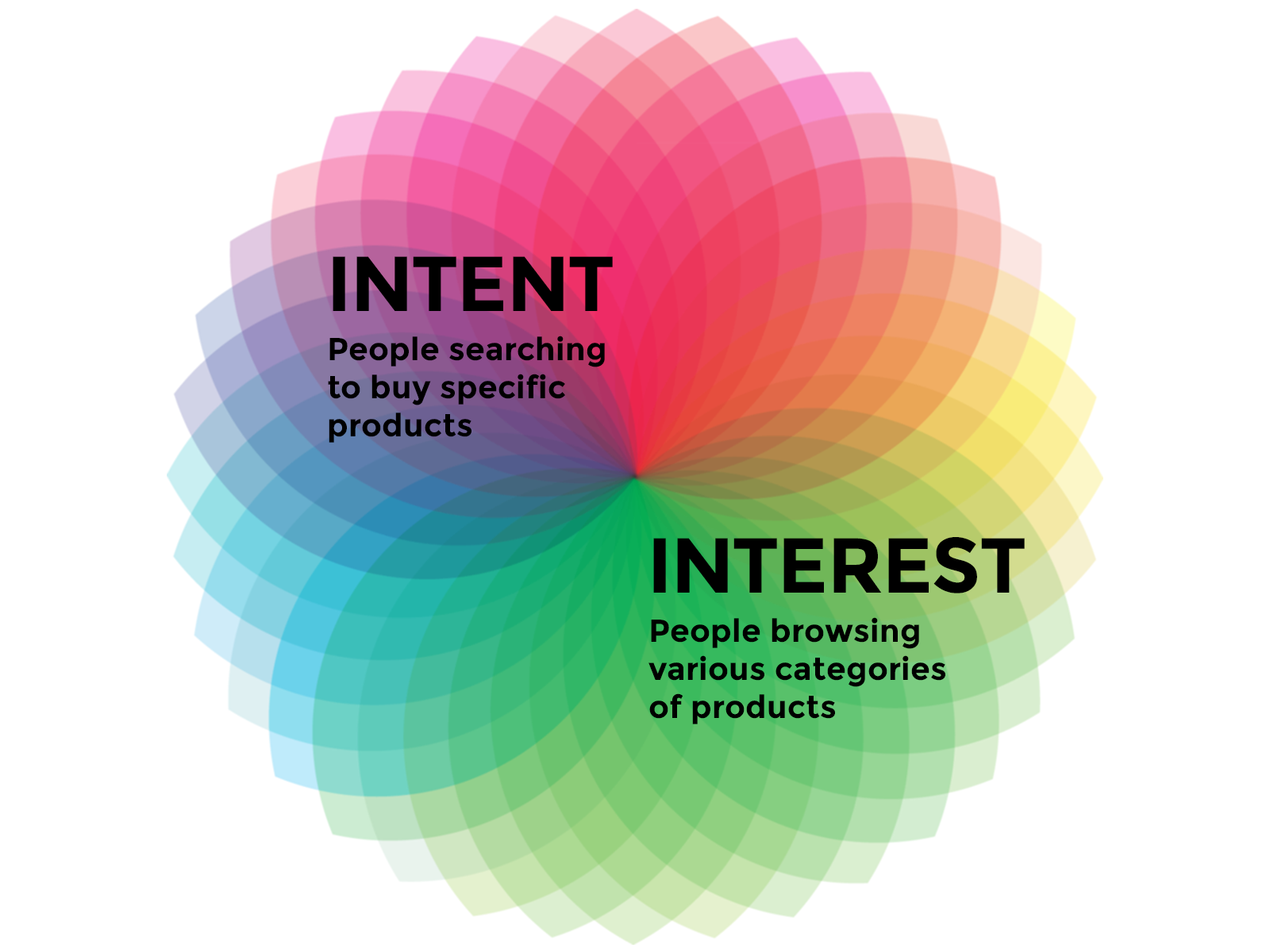
Un número de usuarios de Flipkart fueron entrevistados para entender cuándo y cómo compran online de forma general. Se hizo evidente que personalizar una transmisión más corta, con un contenido más pulido y productos relevantes sería más cautivante para ellos. Todos estamos familiarizados en cómo los sistemas de recomendaciones tradicionales funcionan al cristalizar patrones de uso e historia. Pero para Flipkart, esto sólo resolvería parcialmente el problema. Entonces, aprendimos que los usuarios suelen comprar de acuerdo a dos grandes temas:
- Propósito: Las personas buscan por productos específicos que tienen en mente. Esto mostró que es crítico capturar y tener un seguimiento de las búsquedas de los consumidores de forma individual.
- Interés: Una conducta mucho más amplia de ‘mirar vidrieras’ y buscar productos en varias categorías que al usuario le guste, o cae dentro de sus intereses. Es mucho más sobre preferencias y tendencias. Por ejemplo, alguien podría tener interés en salud y bienestar, en irse de mochilero, o momentáneamente buscar un regalo de bodas. Flipkart también tuvo como misión capturar esos aspectos de conductas individuales en los consumidores.
Clasificación vs. Temas Interconectados
Para reducir millones de productos en una transmisión de información digerible de un par de productos, necesitábamos pensar muy bien cómo hacer que productos de varias categorías fueran relevantes para un cliente.
Evaluando perfiles de usuarios, observamos que la acción de comprar suele ocurrir en temas. Asignamos un set de meta-etiquetas a cada producto, y con cada etiqueta llegando al punto donde una senda de productos se cruzan, relacionados por tema. En vez de agrupar por categorías y organizar de forma tradicional por clasificación, revisamos nuestro acercamiento y organizamos los productos en temas e historias.
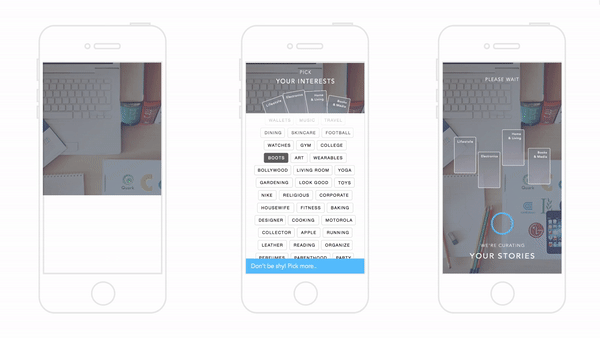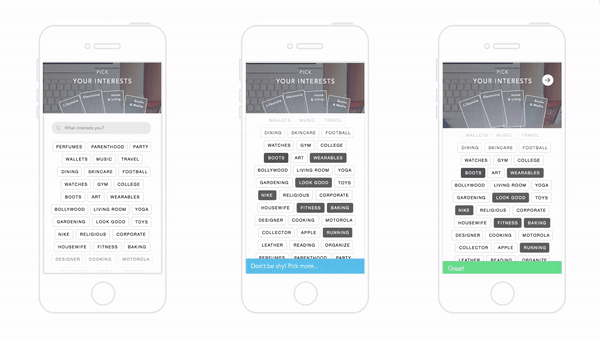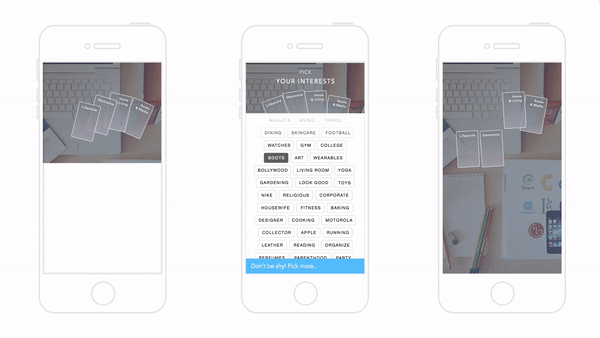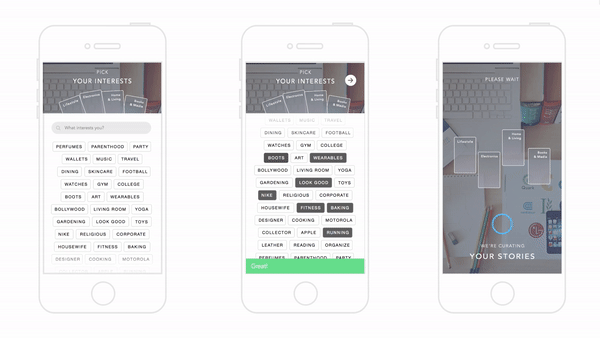
El universo resultante era una combinación de fuertes y holgadas galaxias de productos ligadas e interconectadas—sirviendo como ambos patrones de compra de interés y propósito—que fue construído de forma única para cada usuario. Debajo hay una red para “Viajes”:
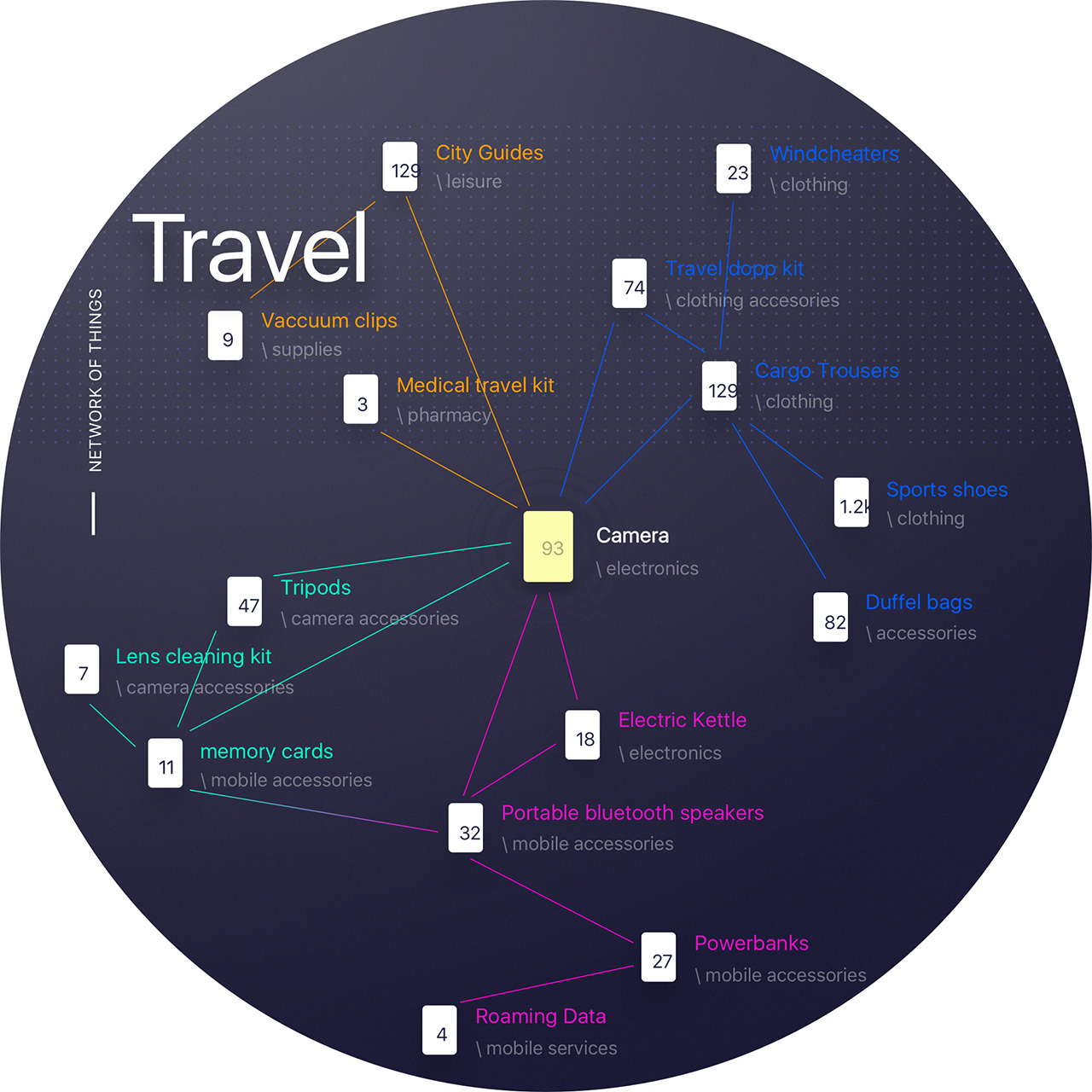
El objetivo de la compañía era crear una condición donde, por ejemplo, un cliente pueda ver un producto y explorar productos relacionados en esa historia o tema como si viajara a través de esa galaxia. Este acercamiento le permitió a usuarios ver una colección diversa de productos divididos por su categoría, pero unidos por su historia o tema.

La Solución: Un Resumen Diario y Corto
Internet es grande y muchas veces parece interminable. Los consumidores sofisticados de hoy en día quieren información relevante, no información en abundancia. Esto significó que el motor de las recomendaciones de Flipkart debían ser reconstruidas desde sus cimientos.
Transmisiones Infinitas vs. Finitas
Decidimos construir un resumen diario de un número limitado de productos, actualizando dicho resumen cada día. Esto significó que podíamos movernos de una lista infinita de productos, lo cual por lo general dejaba al usuario en un estado de parálisis de decisión, lo cual se convertía en algo obsoleto y terminaba en algo muy irrelevante y consecuentemente ignorado.
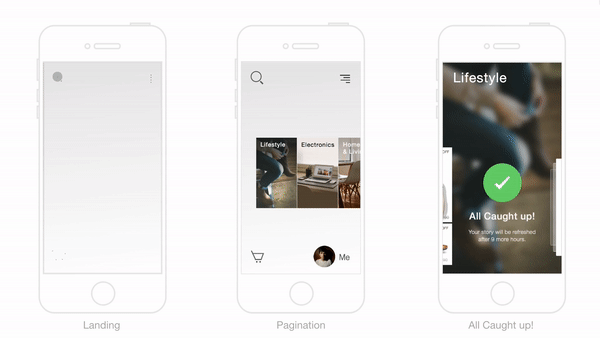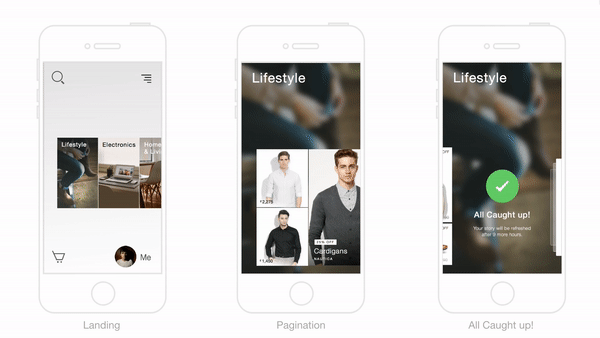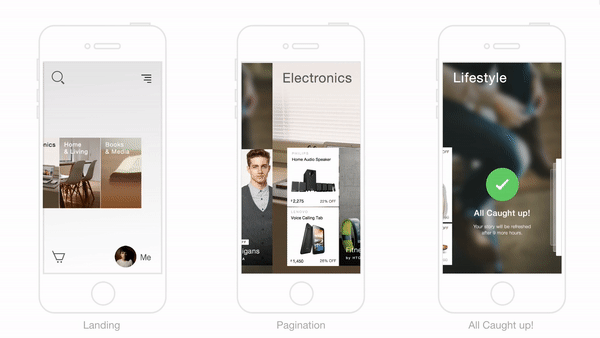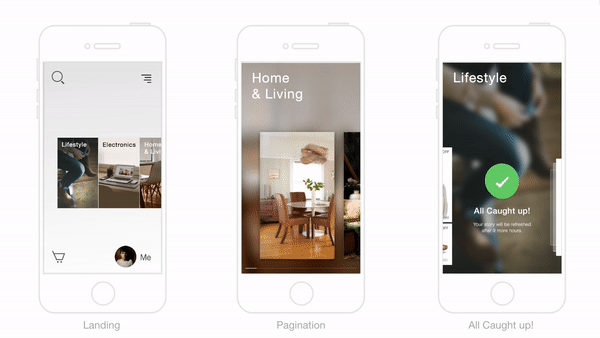
Trabajando El Gancho Para Formar Hábitos Exitosos En La Experiencia De Compra
En el corazón de la solución de Flipkart yace la decisión de usar el concepto del “gancho” para crear una experiencia de usuario que forme hábitos diseñados para atraer a los clientes al sitio de eCommerce.
Sabíamos que los usuarios se apegarían a la anticipación de recibir una potencial recompensa, y por eso se nos ocurrió el concepto del resumen diario, lo cual estaría organizado alrededor de temas e historias, y personalizadas de forma individual para cada usuario.
El camino en el que se apoyó Flipkart para un resumen diario bien diseñado se convirtió en algo bastante familiar con los hábitos existentes de sus clientes. Al entender qué hace que los clientes compren y consuman, y presentarles un número finito de ofertas que Flipkart sabía que serían de su agrado, pudimos tomar ventaja de sus hábitos de compra mobile ya arraigados.
En vez de intentar cambiar los hábitos de los consumidores o convencerlos de los méritos de Flipkart, les dimos un nuevo recurso para agregar a su existentes conductas de FOMO.
Todos en el espacio del eCommerce está compitiendo por un pedazo de lo que se predijo para el 2020 como el mercado global de los $4 trillones de dólares. Las compañías que se equilibraron para salir primeras son aquellas que pensarán exitosamente algo fuera de lo común e implementarán una estrategia en experiencia de usuario diferente de algo más tradicional.
El futuro del eCommerce está atrayendo a clientes con recomendaciones relevantes y personalizadas, construidas alrededor de datos de usuario, y no simplemente sirviendo como un catálogo de productos que empuja al usuario hacia productos que los sitios quieren que compren.



